Developers Guide to Data Lakehouse with Apache Iceberg
Why it matters? 🚀
- Draws clear line between data storage and computation. Counteracts data gravity force allowing avoiding vendor lock-in.
- Cost optimization. Properly implemented solution allows to get rid of costly, existing data warehouse products.
- Future-proof data architecture. Iceberg’s forward-looking design caters to evolving data sizes and formats, ensuring your data architecture remains scalable and efficient as your needs grow.
- With features like atomic transactions and consistent updates, the solution ensures data reliability and integrity, minimizing the risk of data loss or corruption.
Your levarage 🃏
- Gain practical insights into deploying a Data Lakehouse solution that rivals industry-level data warehouses, with step-by-step instructions tailored for developers.
- Learn how to implement and benefit from powerful features like time travel, schema evolution, and hidden data partitioning, enhancing your ability to manage and analyze data effectively.
- Access a ready-to-use template for setting up a local research environment leveraging MinIO, and integrate with popular query engines like Apache Spark and Trino for a comprehensive development experience.
Apache Iceberg 101
Apache Iceberg, introduced by Netflix, stands as a premier open table format implementation designed to address three critical challenges in data processing:
- Atomic Transactions: Ensures that unsuccessful updates or appends do not corrupt the system state.
- Consistent Updates: Maintains read consistency and integrity during write operations, even amidst potential conflicts from concurrent updates.
- Data & Metadata Scalability: Eliminates common bottlenecks associated with object store APIs and metadata management as tables expand to encompass thousands of partitions and billions of files.
Apache Iceberg acts as an intermediary layer that abstracts the physical data storage from its organizational structure, positioning itself between the data query engine and the stored data.
Iceberg offers a robust solution to these issues. Unlike Hive, which requires both a central metastore for partition management and a file system for individual files, Iceberg employs a more efficient approach. It utilizes a tree structure stored within a snapshot to list all data files, thereby enhancing performance and scalability.
Each data modification — be it an addition, deletion, or update — generates a new snapshot that leverages as much of the preceding snapshot’s metadata as possible. The system stores valid snapshots in the table’s metadata file, alongside a reference to the current snapshot. By replacing the path of the current table metadata file with an atomic operation during commits, Iceberg ensures atomicity in all updates to table data and metadata. This mechanism underpins the model for serializable isolation, yielding several beneficial properties:
- A linear, immutable history of table modifications
- The ability to roll back to previous table states (time travel)
- Enhanced security and integrity for file-level operations
Iceberg supports multiple concurrent writes using optimistic concurrency.
Each writer assumes that no other writers are operating and writes out new table metadata for an operation. Then, the writer attempts to commit by atomically swapping the new table metadata file for the existing metadata file.
If the atomic swap fails because another writer has committed, the failed writer retries by writing a new metadata tree based on the new current table state.
Table Specification Overview
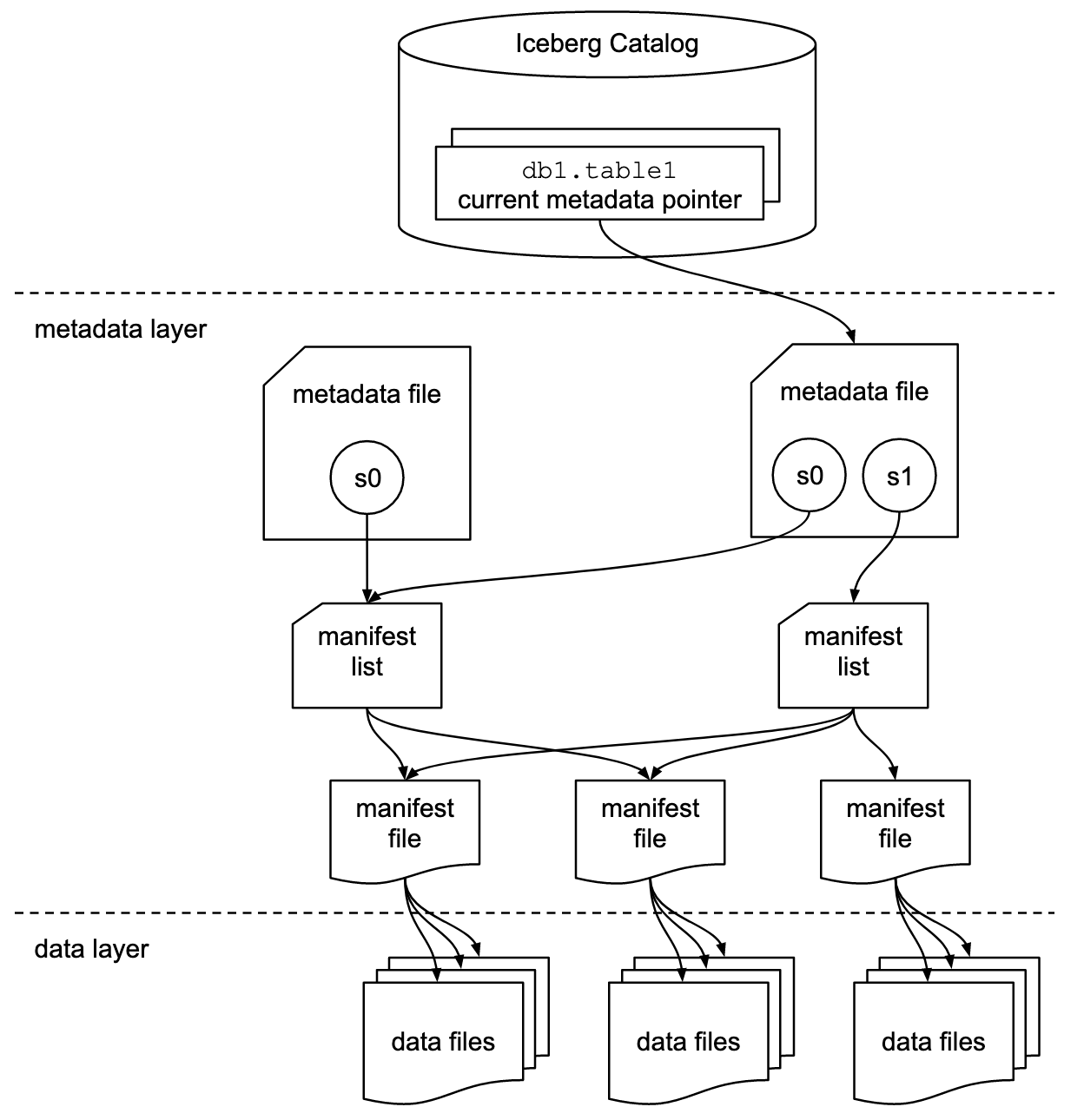
Overview of Iceberg Table Spec (source).
The Iceberg table specification includes several key components, starting from the base level:
- Data Files: The physical files that store data, formatted as Parquet, Avro, or ORC.
- Manifest Files: These files list the paths to related data files along with metadata for query optimization.
- Manifest List: Facilitates the reuse of manifest files across snapshots, enhancing efficiency.
- Metadata Files (snapshot): Tracks the current state of the table, including schema, partitioning configuration, and snapshot history.
- Catalog: Points to the latest snapshot of the table, ensuring up-to-date data access.
Get the Iceberg Architecture Cheatsheet
One-page visual reference: table spec hierarchy, snapshot mechanics, and metadata structure. Pin it next to your terminal.
Infrastructure
Our local infrastructure is composed of two distinct layers: data and computation. For the object storage, we have selected MinIO, a solution that is fully compatible with the AWS S3 API, serving as a seamless drop-in alternative. Additionally, a Postgres database will be utilized to maintain the current metadata of tables. When it comes to the query engine, Spark emerges as our primary selection due to its comprehensive feature set, making it the leading choice in its field. However, we are also exploring the potential of integrating Trino to enhance our capabilities.
Commander Bun Bun
Facebook has been a trailblazer in the data engineering domain, initially developing Apache Hive to enable querying data via the Hadoop cluster, thus introducing the first-generation table format.
However, four years later, in 2012, Hive struggled to meet the demands for interactive queries as the cluster processed approximately 250 petabytes of data. This limitation led Facebook to initiate a new open-source project aimed at reading data directly from its source through a versatile connector system. This project was Presto, with its first connector designed for Hive. Presto quickly transitioned to production use, attracting attention from major companies like Netflix and LinkedIn.
The project’s momentum continued to accelerate, with significant contributions from Teradata, enhancements to AWS’s EMR offerings, and Starburst’s endeavors to promote Presto’s adoption across various platforms.
In 2020, to distinguish it from older versions, the project was rebranded as Trino, encapsulating its mission to enable “SQL at Any Scale, on Any Storage, in Any Environment.”
Environment setup
Explore the Github repository for detailed instructions on replication.
The JDBC Metadata Catalog is preferred in this exercise for a two reasons: (1) it receives support from both Spark and Trino, making it highly compatible, and (2) it provides an accessible means to delve into the intricacies of Iceberg’s internal mechanisms.
For instances involving local, less intensive use, the HadoopCatalog presents a viable option (link). This method relies on maintaining a version-hint.txt file within the storage bucket to reference the most recent snapshot revision. An example of Spark’s Hadoop catalog configuration is available in the GitHub repository. Conversely, for more rigorous, production-level applications, opting for a RestCatalog is advisable, with Project Nessie being a recommended choice.
To commence, it is essential to arrange both the primary storage bucket for the data—specifically, s3://whjdbc — and the metastore’s table structure.
Securing the storage bucket is straightforward and can be achieved through various methods. Regarding the metastore setup, the JdbcUtil1 class within the Iceberg source plays a crucial role by generating the necessary SQL statements. Following the guidance of the Trino documentation2, the simplest and recommended approach involves utilizing a Spark client to automatically establish a table:
| |
By configuring the cat_jdbc catalog within Spark, a new database named db is created, housing an events table. Consequently, this action results in the creation of two essential tables within the metastore:
iceberg_namespace_properties,iceberg_tables
The iceberg_tables table contains a record that points to the latest snapshot file, as illustrated below:
| catalog_name | table_namespace | table_name | metadata_location | previous_metadata_location |
|---|---|---|---|---|
| cat_jdbc | db | events | s3://whjdbc/db/events/metadata/00000-7e748b46-918c-41c4-9cf7-c155d79d490a.metadata.json | NULL |
You can look at the metadata file contents below:
| |
Here is my advice for running SQL queries in VSCode. Adding this keybinding will transfer the line to the underlying terminal process. Works great with DuckDb or Spark SQL. Even better with SQLFluff.#dataengineering #vscode pic.twitter.com/yfWxTWHwnA
— Norbert Kozlowski (@don_khozzy) February 8, 2024
Dive into Apache Iceberg
Upon establishing the table framework, it’s time to populate it with data. The following Spark SQL commands illustrate how to insert records into the cat_jdbc.db.events table:
| |
Several actions occur upon executing these commands:
- The data is stored in the bucket’s
data/directory as Parquet files, which is the default storage format. - The pointer to the table’s latest snapshot in the catalog (
metadata_location) is updated. - A new metadata file is generated and enriched with a
snapshotsproperty. This property provides concise statistics about the latest operation and includes a reference to the manifest-list file, as shown in the snippet below.
| |

Preview of the manifest-list file (Avro extracted using online tools). You see list of manifest entries with corresponding statistics.
With the data now securely in place, querying it using standard SQL syntax becomes straightforward. For instance:
| |
We ensure that our transactions adhere to ACID principles for data integrity. To demonstrate the robustness of these transactions, let’s perform a series of operations, each appending a new snapshot to the metadata file:
| |
Data modification within a system can be conducted through two primary approaches: Copy-on-Write and Merge-on-Read. By default, the system utilizes the Copy-on-Write strategy, but users have the flexibility to alter this setting via the write.[update|delete|merge].mode properties. Conversely, Merge-on-Read is specifically supported by version 2 of the Iceberg table format specification, a detail verifiable atop the metadata file.
Copy-on-Write: This method involves rewriting the entire file even if only a single row requires modification. Consequently, a new snapshot is created to reference the most recent version of the data file.
Merge-on-Read: Unlike Copy-on-Write, this strategy does not rewrite the existing data file. Instead, it generates a new delete file that logs which records have been eliminated, utilizing either “Positional Delete Files” or “Equality Delete Files” based on the query engine interface. When executing a query, the system refines the results by incorporating the information from the delete files.
The choice between these two modes hinges on specific data access patterns. The Copy-on-Write approach is particularly advantageous for scenarios with frequent data reads, albeit less efficient with regular writes. On the contrary, Merge-on-Read is optimized for write efficiency by avoiding complete data file rewrites, though it necessitates additional processing during data reads to amalgamate information from multiple files.
It is critical to understand that in both methodologies, data is NOT physically deleted and remains accessible, for instance, through time-travel functionalities by referencing particular snapshots. To manage data effectively, it is recommended to establish table snapshot expiration policies or to implement an asynchronous task that invokes the expire_snapshot procedure.
Schema evolution
Iceberg revolutionizes schema evolution, handling additions, deletions, renamings, updates, and reordering of columns with unmatched finesse compared to Hive. In the realm of Hive, the extent of functionality is tightly intertwined with the underlying file format. For instance, operations involving deletions are straightforward with column-name-based formats such as Parquet. However, challenges arise with position-dependent formats like CSV, where such operations become more complex and prone to user errors, especially if an unsupported operation is mistakenly applied to an inappropriate table.
It stands out by ensuring data integrity and offering correctness guarantees through its selective support for a compact set of columnar file types (namely Parquet, Avro, and ORC). These types proficiently embody an internal schema directly within each file, thereby ensuring that schema modifications are seamlessly mirrored as metadata alterations without impacting the actual data files. Furthermore, Iceberg introduces a unique column ID system, effectively eliminating the potential for complications arising from cyclical changes, such as the rotation of column names.
Consider the following SQL commands executed in Trino, which demonstrate Iceberg’s capability to add and then rename a column without hassle:
| |
Iceberg maintains all table schemas within a dedicated metadata file, further enhancing its robustness and reliability in managing schema evolution.
Hidden partitioning
Understanding the complexities of Hive’s partitioning can be challenging. For instance, partitioning data by a timestamp field necessitates the creation of a derived column (such as a date) and ensuring its placement as the last column in the table’s DDL of VARCHAR type. This often results in duplicated data and the need to guide the table’s consumers on which column to utilize for efficient data querying.
Iceberg addresses these challenges by employing an internal partition specification. This approach obviates the need for users and consumers to be aware of the partitioning details to benefit from it. Iceberg allows for partitioning by year, month, day, and hour granularities and supports the use of categorical columns to cluster rows for faster query performance. Furthermore, the partition layout can be updated smoothly as requirements evolve3.
| |
Subsequently, one can examine the layout of the object storage directory. Partitions directory layout in Minio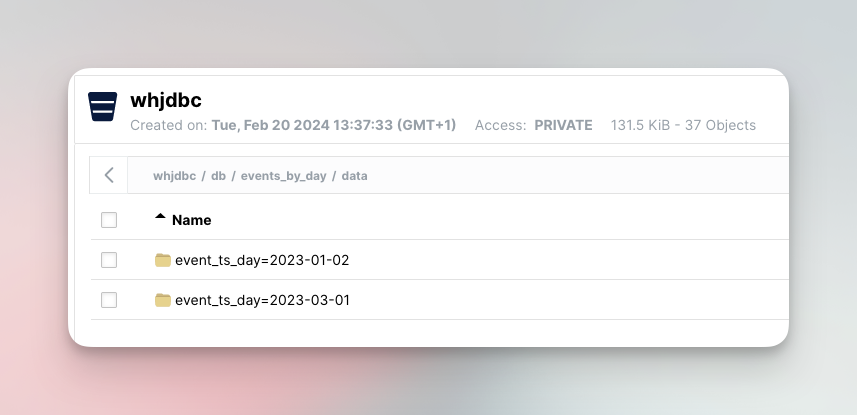
Iceberg also facilitates the partitioning of existing tables. New data is partitioned according to the new specification, and results are integrated during query execution.
To repartition an entire table while preserving all historical snapshots, the CREATE TABLE AS ... or REPLACE TABLE ... AS SELECT atomic operations may be utilized45.
| |
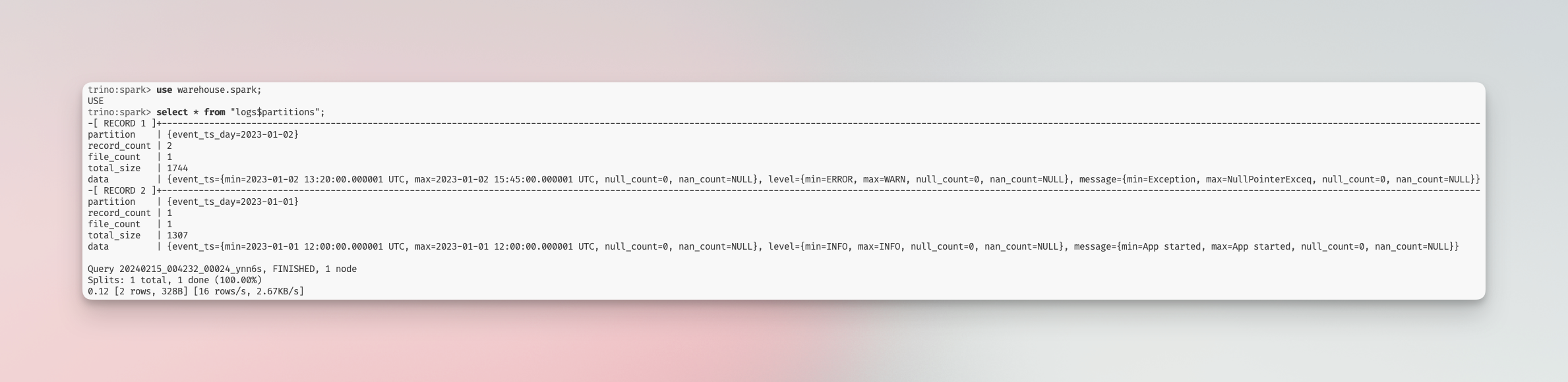
Leverage the physical query plan generated by query engines to ensure that only relevant data segments are scanned.
| |
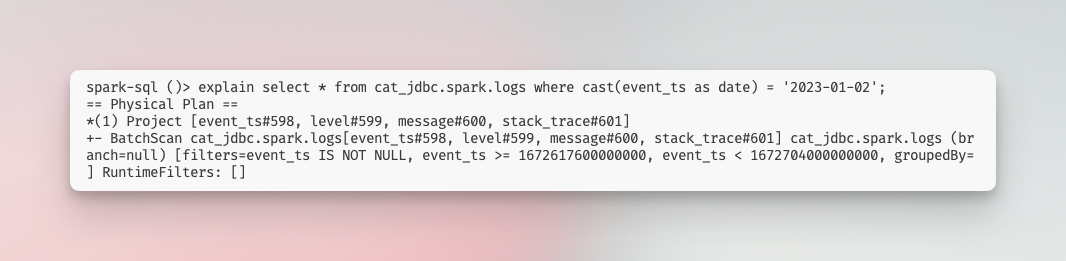
Unfortunately, the query plan in Spark does not initially appear informative enough to confirm if predicate pushdown is effectively applied. However, a discussion in this thread suggests that if the BatchScan operation is configured with the filters attribute, the feature is functioning as intended.
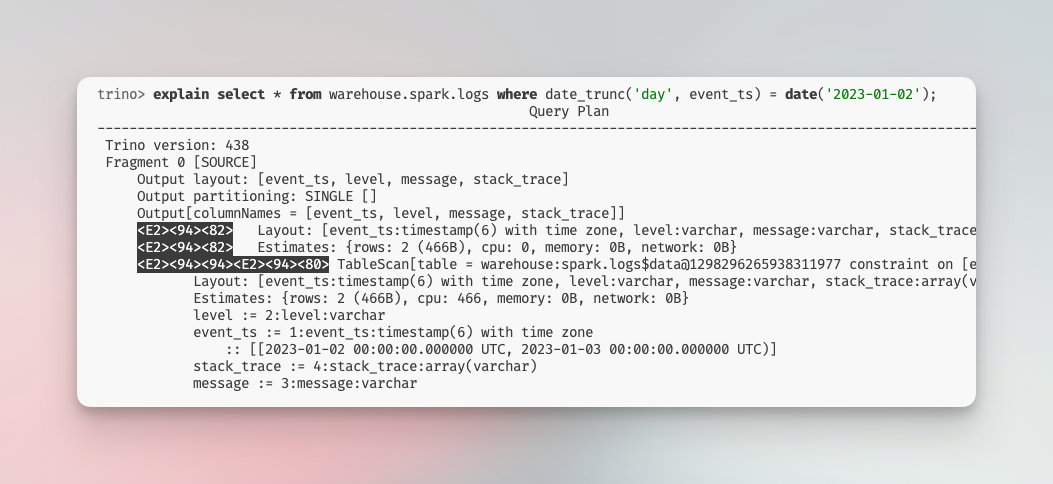
Documentation on Trino predicate pushdown supports the assertion that the feature operates effectively: If predicate pushdown for a specific clause is successful, the EXPLAIN plan for the query will not include a ScanFilterProject operation for that clause.
Time travel
As we delve deeper into more complex functionalities, the concept of time travel in data management comes to the forefront. This capability allows for querying historical data in two primary ways:
- Using a Snapshot Identifier: This method involves specifying the unique snapshot identifier that correlates with the desired version of the data table you wish to access.
- Point-in-Time Retrieval: Here, you specify a particular timestamp. The system then accesses the most recent snapshot of the table that existed before the given timestamp.
Consider the following SQL examples for practical application:
| |
For those requiring advanced snapshot lifecycle management, tagging specific snapshots introduces a new layer of flexibility. Tagged snapshots, or branches, benefit from their lifecycle management, independent of standard cleanup processes such as expire_snapshots. This functionality is especially valuable for compliance with regulations like GDPR, or within data engineering workflows that adhere to patterns such as Write-Audit-Publish.
| |
It’s important to note that time travel queries can retrieve data that has been altered or removed since the time of the snapshot, providing a powerful tool for data analysis and audit trails.
Maintenance
Iceberg is often used in conjunction with streaming data, leading to the creation of numerous small files. While these files are inexpensive to write, they are less efficient for querying. Ideally, managing fewer, larger, and better-organized files would enhance performance.
Thankfully, Iceberg supports several maintenance procedures that are essential for optimal performance. These include the compaction of small files, expiration of snapshots, removal of outdated metadata files, and the deletion of orphaned files. Regular execution of these procedures is recommended.
Files compaction
A large number of small files can significantly increase I/O overhead due to the need to open, read, and close each file. To mitigate this, it is advisable to consolidate files into larger sizes, aiming for 128MB, 256MB, or 512MB, which are more efficient for read operations.
Iceberg employs the rewrite_data_files procedure for file compaction6, targeting a default file size specified by the write.target-file-size-bytes table property, typically set to 512MB.
| |
While Spark SQL offers finer control over the optimization process, Trino automates this process to a greater extent7. Importantly, when leveraging merge-on-read for row-level updates and deletions, compaction also resolves delete files, enhancing read efficiency by eliminating the need to merge delete files during read operations. Note that nothing is deleted and old files can still be referenced with time travel.
binpack - The default and fastest strategy, aiming to rewrite smaller files to a target size while resolving any delete files without further optimizations like sorting. It is recommended to limit the scope of the procedure using the where clause to avoid processing the entire table.
sort - An extension of the binpack strategy that incorporates data sorting to improve performance. Iceberg leverages file statistics to minimize unnecessary file parsing, with sorting conditions specified via sort_order arguments. Z-Ordered sorting is also available, giving equal weight to each dimension.
Expire snapshots
Table snapshots, which are created during table evolution or writing, enable time-travel capabilities. Over time, however, an accumulation of snapshots can lead to increased storage costs. The expire_snapshots procedure, available in both Spark8 and Trino9, facilitates the removal of unused snapshots and their associated data.
| |
older_than and retain_last arguments are removed the table’s expiration properties will be used.Removing obsolete metadata files
Similar to the process with snapshots, each new write operation to a table generates a new metadata file. Over time, the accumulation of these files can become burdensome. Fortunately, specific settings allow for the management of this issue10:
write.metadata.delete-after-commit.enabledenables the deletion of old tracked metadata files following commits (default setting:false),write.metadata.previous-versions-maxdetermines the maximum number of metadata files to retain (default setting:100).
Orphan files removal
Files that are not referenced by any snapshot or metadata, known as orphan files, may accumulate as a result of interrupted operations or failed jobs. These files are elusive because they are not tracked, rendering them invisible to procedures such as expire_snapshots or the removal of outdated metadata files.
The remove_orphan_files procedure11 scrutinizes all valid snapshots and cross-references the data files with those in the data/ directory on the storage system. It’s important to note that this process can be extensive and may encounter certain complications, such as files in transit, table migrations, or dealing with multiple data locations.
| |
AWS Athena enables the OPTIMIZE and VACUUM operations1 to compact data files and delete snapshots and orphans accordingly.
Get the Iceberg Architecture Cheatsheet
One-page visual reference: table spec hierarchy, snapshot mechanics, and metadata structure. Pin it next to your terminal.
Extra
GDPR / US State Data Protection Law
A critical aspect of GDPR compliance involves understanding the specific data an organization possesses and identifying the individuals it pertains to. This requirement necessitates that data be systematically structured, organized, and readily searchable.
Utilizing Apache Iceberg, complete with full DML and SQL support, ensures that data is meticulously structured, organized, and effortlessly searchable. The capability to implement branching facilitates the capturing of data snapshots at specific moments for audit purposes.
Organizations under the purview of GDPR are obligated to accommodate data subject requests promptly. Individuals now have considerably enhanced rights, including inquiries about the type of data held by an organization, requests for access to or correction of their data, the deletion of their data, and/or the transfer of their data to a new service provider. Consequently, organizations must be able to efficiently search their business systems to locate all personal data associated with an individual and take appropriate action.
The Iceberg framework’s support for atomic transactions, consistent updates, and ACID compliance ensures its adequacy for managing the retrieval, updating, and deletion of individual data requests. Moreover, snapshot expiration protocols facilitate the elimination of obsolete information or personally identifiable information (PII) from storage systems (link).
Additionally, data can be encrypted at multiple levels to provide further security measures. Options include encrypting the entire storage layer (e.g., using AWS KMS) or individual Parquet files at rest. The application of key rotation techniques, such as assigning a unique encryption key to each customer, further enhances data security.
Resources
- https://medium.com/expedia-group-tech/a-short-introduction-to-apache-iceberg-d34f628b6799
- https://github.com/zsvoboda/ngods-stocks
- https://github.com/ivrore/apache-iceberg-minio-spark
- https://blog.cloudera.com/optimization-strategies-for-iceberg-tables/
- https://www.guptaakashdeep.com/copy-on-write-or-merge-on-read-apache-iceberg-2/
- https://www.dremio.com/blog/maintaining-iceberg-tables-compaction-expiring-snapshots-and-more/
https://github.com/apache/iceberg/blob/main/core/src/main/java/org/apache/iceberg/jdbc/JdbcUtil.java ↩︎
https://trino.io/docs/current/connector/metastores.html?highlight=jdbc#jdbc-catalog ↩︎
https://iceberg.apache.org/docs/latest/evolution/#partition-evolution ↩︎
https://iceberg.apache.org/docs/latest/spark-ddl/#replace-table-as-select ↩︎
https://trino.io/docs/current/connector/iceberg.html#replacing-tables ↩︎
https://iceberg.apache.org/docs/latest/spark-procedures/#rewrite_data_files ↩︎
https://trino.io/docs/current/connector/iceberg.html#optimize ↩︎
https://iceberg.apache.org/docs/latest/spark-procedures/#expire_snapshots ↩︎
https://trino.io/docs/current/connector/iceberg.html#expire-snapshots ↩︎
https://iceberg.apache.org/docs/latest/maintenance/#remove-old-metadata-files ↩︎
https://iceberg.apache.org/docs/latest/spark-procedures/#remove_orphan_files ↩︎