From Ingestion to Insight: Creating a Budget-Friendly Data Lake with AWS
Why it matters? 🚀
- The solution is equipped to handle both structured and unstructured data, a crucial aspect for both analytical and engineering tasks.
- It is capable of facilitating both real-time streaming and batch data processing.
- With proper configuration, it proves to be cost-efficient and scalable; both storage and processing tiers are decoupled and highly optimized.
- The solution adheres to regulatory and compliance requirements, ensuring data protection and the safeguarding of sensitive information.
What you will learn?
- How specific AWS services synergize to provide a serverless data platform.
- A no-code approach to establishing an infrastructure capable of collecting, transforming, and querying underlying data with minimal cost implications.
- The practical distinctions between representing files in JSON and Parquet formats.
- Techniques for querying streaming data in quasi real-time using the SQL language.
Story background
Imagine being the owner of a cutting-edge bio-hacking startup. Naturally, your focus lies in meticulously monitoring user behavior, uncovering invaluable insights, and computing pertinent metrics that stand up to the scrutiny of potential investors.
Since the initial release of your app, during the early stages of the telemetry process, you made the strategic decision to meticulously track three fundamental events: the occurrence of an anonymous_app_visit, the completion of an account_registration, and the creation of a measurement_record (which signifies users inputting their medical data for subsequent analysis).
Anticipating an exponential surge in user growth in the near future, we are actively preparing a robust, scalable, and highly secure mechanism for efficient data collection. To expedite the development progress, a set of user sessions was modeled as a Markov Decision Process, where each state carries a specific transition probability.
In preparation, we have compiled a synthetic dataset comprising 100,000 distinct user sessions, each encompassing one or more events. This dataset will be utilized in the exercises ahead (source code). To emulate real-world scenarios, intentional inclusion of duplicated events adds an extra layer of authenticity.
Layman’s system architecture
In the initial approach, our strategy involves creating a dedicated service process that exposes an HTTP collector endpoint. This process performs the initial data processing and subsequently transmits the processed data downstream for storage, either in a database or a file system.
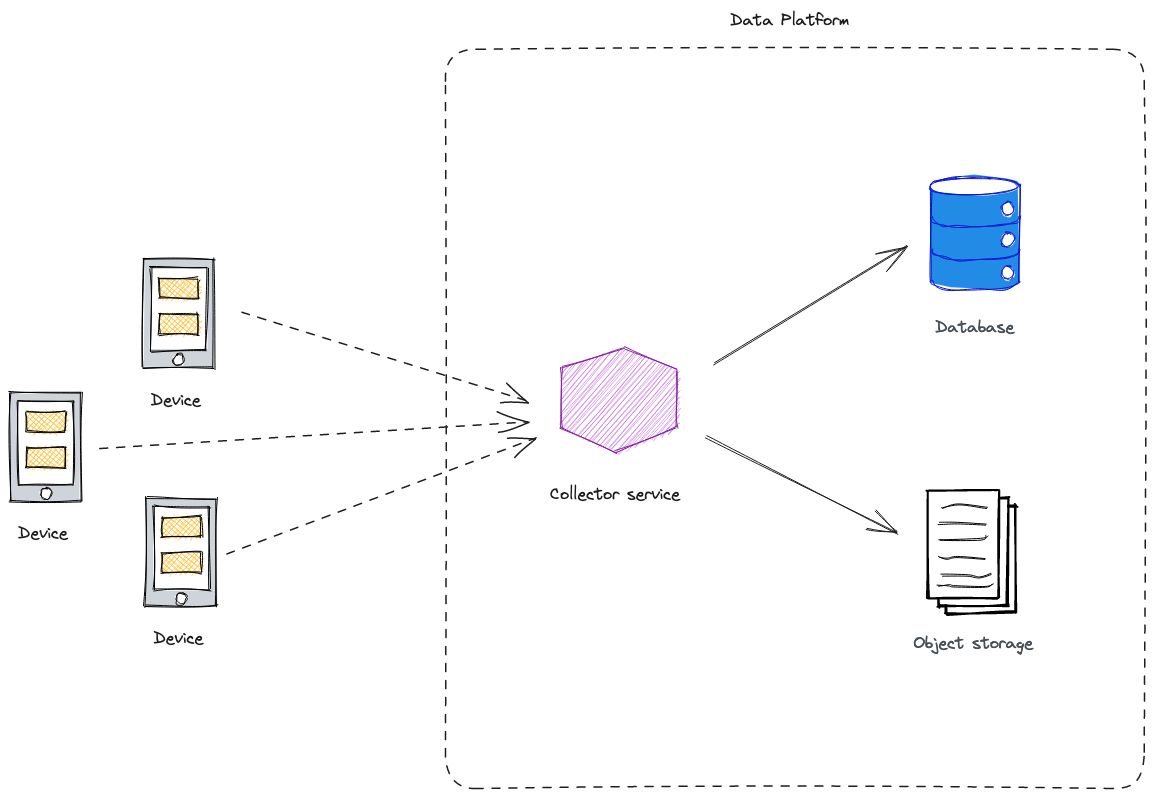
Naive Approach System Architecture.
While this design could be functional, it comes with several notable drawbacks:
- Scalability Challenges: The allocated resources might struggle to manage high levels of incoming traffic.
- Maintenance Complexities: Introducing each new proprietary component adds to the overall system complexity and maintenance workload.
- Reinventing the Wheel: There’s a risk of duplicating efforts by independently handling exceptional cases and communication with other system components.
We understand the importance of optimizing our engineering resources and avoiding unnecessary upkeep. That’s why we’re excited to present a more refined proposal that addresses these concerns.
Native components of Amazon AWS
To accomplish the goal we put the following AWS services in our crosshairs:
- The Kinesis Data Firehose service: This allows us to securely ingest and store incoming payloads.
- S3 and Glue: These form the storage layer and logical data catalog, ensuring efficient data management.
- Athena: As a query engine, Athena enables us to access underlying data using declarative semantics.
🚨 Attention: Data Security 🚨
Given our engagement with medical records, we must uphold rigorous regulations pertaining to sensitive data. Potential legal violations or data breaches could have severe consequences for our company.
By implementing data encryption measures for both data at rest and data in transit, we can effectively fulfill regulatory and compliance prerequisites for data protection, thus ensuring the safety of sensitive information.
We have the opportunity to utilize the cryptographic capabilities offered by Amazon AWS, which have been specifically designed to fulfill diverse compliance requirements such as GDPR, HIPAA, and PCI DSS. Amazon AWS undergoes regular audits and certifications to validate its security practices and demonstrate its adherence to industry standards.
Storing data as JSON
Kinesis Firehose operates by exposing an endpoint to consume events, subsequently gathering and buffering them for a predetermined duration or data volume. Once these thresholds are reached, it efficiently deposits a batch of data into a predefined location. In our specific scenario, this location is none other than Amazon S3.
For the initial illustration, our emphasis will be on the storage of data in its native form - as JSON objects.
| |
When examining the Terraform resource declaration, we can observe several intricate aspects in play. Let’s begin from the top:
We are making use of the server-side encryption feature. This implies that our data will be automatically encrypted at rest using AWS-owned keys. While it’s also possible to use our own cryptographic keys, we prefer to capitalize on AWS’s compliance certifications, ensuring that your data meets the necessary regulatory requirements.
Moving on, we are configuring the S3 sink. Notably, the implementation involves dynamic partitioning, which allows us to process the contents of each incoming object. Depending on its attributes, we determine the desired storage path. We utilize this technique to construct a Hive-like file path structure. This structure facilitates the utilization of the “predicate projection” feature, which significantly enhances query effectiveness at a later stage. As part of the design, we categorize events by a tuple of name and processing date.
| |
Please take note that the date in the path (prefixed with d=) represents the “message processing timestamp” rather than the event generation timestamp. This deliberate choice aims to facilitate future incremental data processing.
It’s crucial to monitor the total number of partitions within a batch, which are combinations of parameters forming an object path. If this count exceeds the account quotas, Kinesis Firehose will generate the “The number of active partitions has exceeded the configured limit” error.
Subsequently, we make use of data processors to transform and process streaming data before sending it to the destination. In this scenario, each incoming object undergoes processing by the MetadataExtractionQuery processor, which extracts specified parameters from the message payload. These parameters might subsequently be employed to dynamically construct the object path.
Delimiters for text payloads in Kinesis Firehose
Pay close attention to the way the producer emits events. By default, Kinesis Data Firehose buffers incoming payloads by concatenating them without applying any delimiters. Consequently, for a series of incoming JSON messages, the file dropped on S3 might exhibit the following structure:
1{...}{...}{...}This situation is tricky because the stored file does not meet the requirements for a properly formatted JSON file, which could impact downstream processes. Although tools like AWS Athena will continue to operate, they may produce incorrect results that could be challenging to identify initially. In the past, workarounds involved creating custom Lambda functions to add delimiters to records. However, now this task is as simple as configuring the delivery stream properly with the
AppendDelimiterToRecordsdata processor.
Efficient Data Storage with Parquet Format
Let’s proceed to create a secondary Kinesis Firehose delivery configuration, closely resembling the JSON setup mentioned earlier. The primary distinction here lies in our utilization of the “Record format conversion” feature, facilitating seamless real-time data transformation from JSON to the optimized Parquet format.
Observe the configuration block for parquet_ser_de output serializer configuration, which offers the flexibility to define parameters such as compression techniques and HDFS block size. For the sake of a more equitable comparison, we will, however, retain the default settings.
| |
This declaration also necessitates that we specify the schema for the underlying data, which will be defined in the subsequent section.
Skip the Copy-Paste
Get the complete Terraform module for this setup. Both JSON and Parquet Firehose streams, Glue tables, IAM roles—ready to deploy.
Data ingestion
With the Kinesis Delivery Streams now prepared, it’s time to populate them with data. Once our synthetic dataset is generated, we will transfer it in batches using the put_record_batch API operation. This transfer will be done separately for each stream. You can find the source code for this process here.
The dataset itself comprises over 700,000 raw events, amounting to a total storage of 165 MB.
Our aim is to gain an initial sneak peek into how the data is stored and to gather an overview of the statistics for the S3 bucket as a whole.
| |
| |
| |
Both streams have successfully reduced their sizes by almost 4 times, thanks to the chosen data compression method. Notably, Parquet format exhibits slightly superior efficiency due to its internal binary format representation.
Data Querying
With the streaming data being consistently stored in Amazon S3 at regular time intervals, we can now delve into the core of data analysis. Our approach involves harnessing the capabilities of AWS Glue, which offers a sophisticated logical portrayal of the data’s structure. Additionally, we employ AWS Athena, a distributed computing engine.
To initiate the process, we commence by defining the necessary resources for two AWS Glue tables: events_json and events_parquet.
| |
| |
We must deliberately mention each data column within our data and partition keys constituting a path to the object (used for the later “predicate pushdown” optimization). We also set the EXTERNAL property, indicating that the table metadata is stored inside AWS Glue Data Catalog, but the data resides in the external data source (S3).
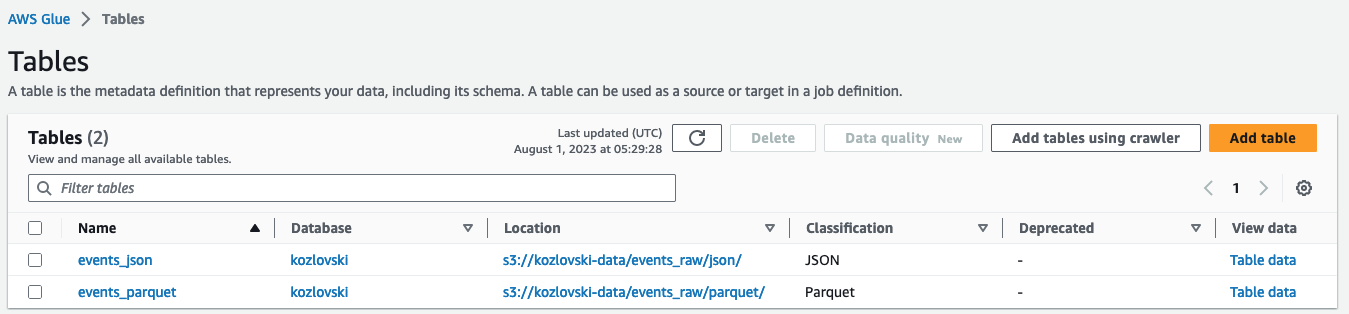
Created tables in AWS Glue web console.
Glue also enables a more automatic way of discovering and registering tables based on the underlying by using Glue Crawlers. However, we prefer to have more control over the process, therefore, declare things manually.
Pro-tip: Occasionally, modifications to AWS Glue tables may not be propagated accurately. If you encounter unusual behavior, it is recommended to delete the table and then recreate it.
Now that everything is in place, let’s attempt to execute some queries in Athena. Interestingly, upon attempting to preview the table, you will notice that there are no results available at this stage. This is because the existing partitions have not been registered in the Glue metastore. There are at least two approaches to resolve this::
- Utilize the
MSCK REPAIR TABLE <table_name>;command to automatically discover the recursive partition structure at the given location. - Alternatively, you can opt for a manual approach for each directory by using the
ALTER TABLE <table_name> ADD PARTITION (event_name="...", d="...") LOCATION "s3://..."command.
It’s important to note that this action needs to be repeated whenever a new partition becomes available.
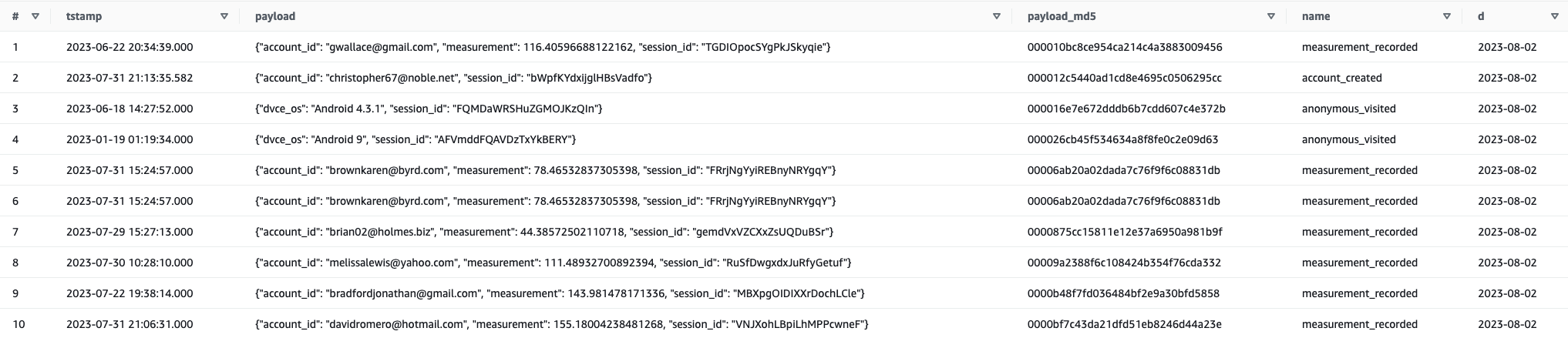
Structure of the events_json table. Notice that partitions appear as a table’s columns.
Let’s imagine that we’re interested in obtaining an aggregated view of anonymous user sessions that occurred in June 2023. The corresponding SQL query could be formulated as follows::
| |
Long story short, we can leverage the declarative SQL syntax alongside proprietary functions (like parsing JSON objects) to model and query the underlying data. Moreover, Athena transiently handles compressed and encrypted data.
Let’s execute the query above using two created tables as a source and observe the metadata.
8.18 MB of data scanned when using the 4.19 MB of data scanned when using the 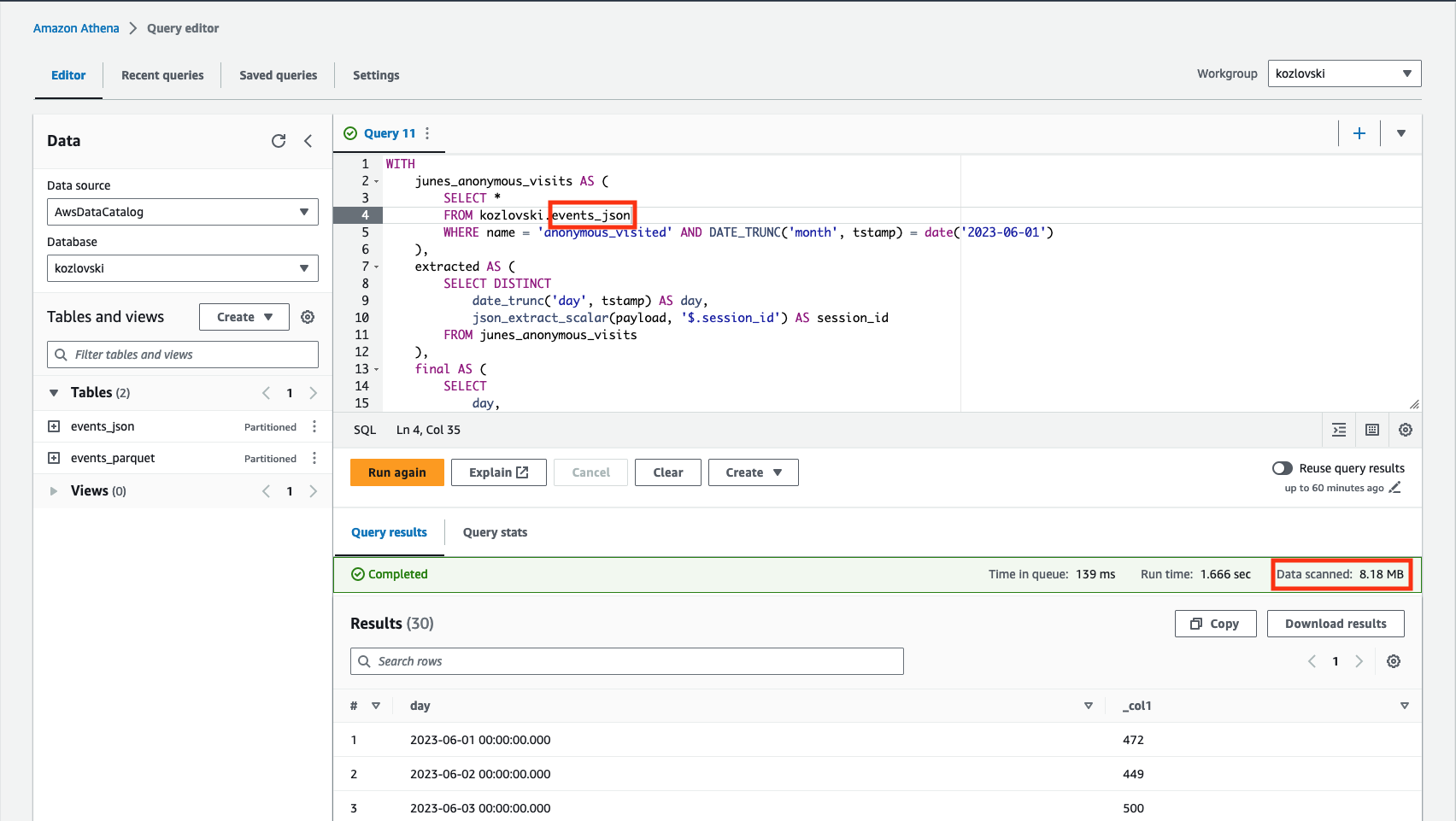
events_json table.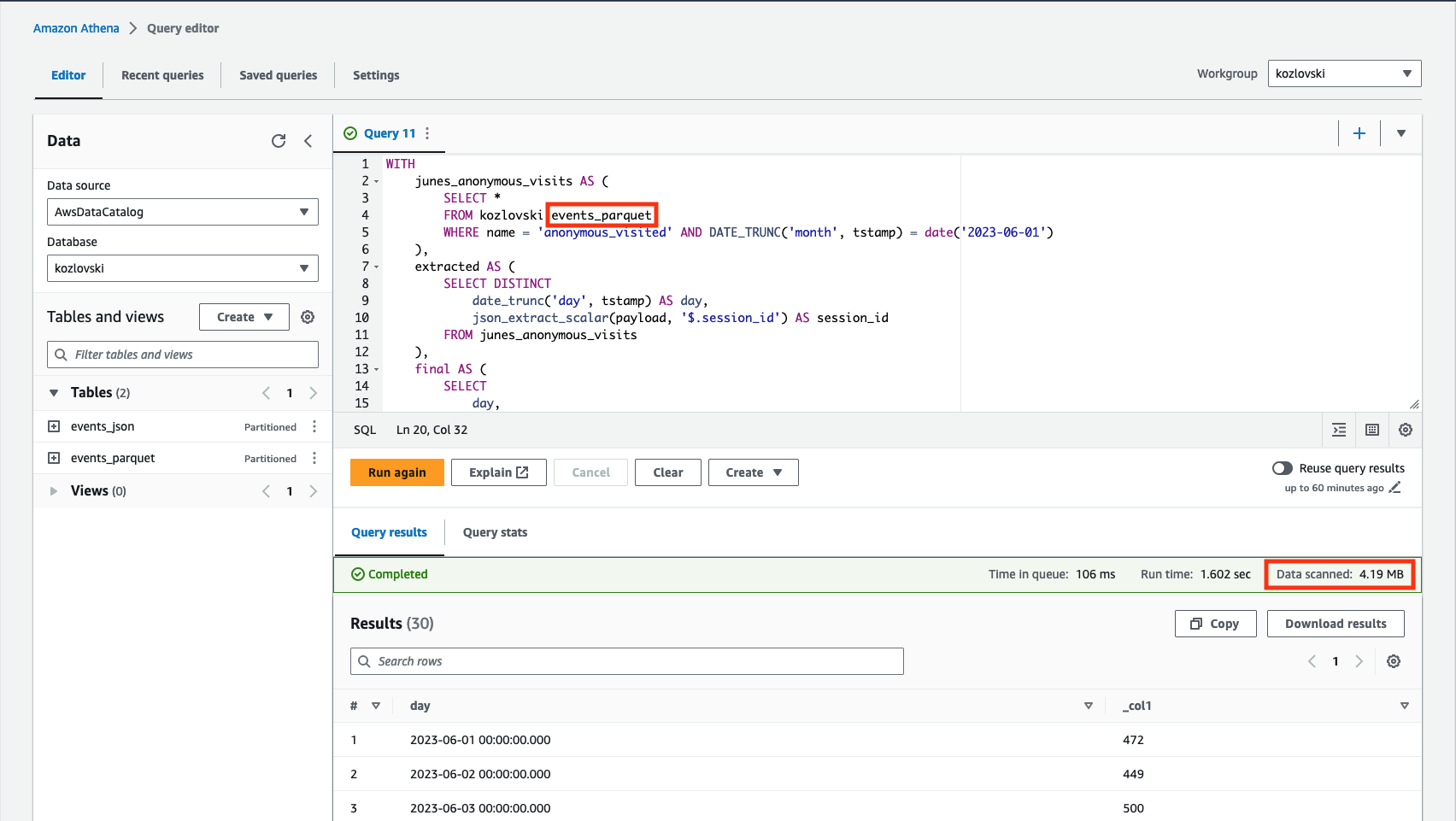
events_parquet table.
In both cases, we see that the amount of data scanned is significantly less than the total data stored on S3 buckets. That is caused by the predicate projection feature, deciding what the location of the objects is - in this case, only anonymous_visited partition is investigated (located in its own subdirectory structure). Utilization of Parquet format is even more efficient by leveraging the predicate pushdown scanning only the relevant portions of the file (containing columns of interest). Since Athena’s pricing model is a function of the data scanned, that directly affects the final AWS bill.
Cost estimation
The projected AWS cost estimates for operating the provided examples amount to less than a dollar. A detailed breakdown is provided below. The largest portion of the cost can be attributed to AWS Athena. It’s important to note that this estimation is based on the assumption of 100 full-scan queries (which might not be very optimal) being executed daily for a month, without accounting for any caching mechanisms. For more information, you can refer to the AWS cost calculator.
| Service | Input (monthly) | Cost |
|---|---|---|
| Kinesis Data Firehose | 700k events (1kB each) | $0.10 |
| S3 | 0.01 GB | $0.00 |
| Glue | 2 tables | $0.00 |
| Athena | 100 full scan queries daily | $0.73 |
| $0.83 |
Closing thoughts
We have observed that AWS Kinesis Data Firehose offers a remarkably straightforward mechanism for achieving scalable data ingestion.
By making use of the concept of “dynamic partitioning”, we can effectively harness the power of “predicate pushdown” by physically organizing rows into directories. Moreover, through the activation of the “Record format conversion” feature, we can seamlessly convert data into Parquet files during the data’s flight. This, in turn, empowers us to further benefit from the “projection pushdown” capability, as it enables the scanning of only those file blocks that contain pertinent data.
While the solution presented represents a great initial stride, it does carry certain noteworthy limitations:
- The optimal efficiency of Parquet files is typically achieved when the file size maintains a range of around 64-128MB. Accomplishing this might involve extending the buffering window of Kinesis Firehose, albeit at the expense of increased solution latency. Presently, the size of generated files is contingent upon the velocity of incoming data, which in turn increases the likelihood of generating numerous smaller files, consequently introducing additional computational overhead.
- To execute queries with efficiency, data analysts are required to possess an understanding of the data partitioning scheme (the physical layout of the data).
- The range of available Data Manipulation Language (DML) operations is rather limited, precluding updates and deletes. Furthermore, a mechanism to control access to the data is noticeably absent.
In the subsequent posts, we will delve into potential strategies for addressing these concerns.
Get the Production-Ready Terraform
Deploy this entire stack in minutes. Kinesis Firehose, S3, Glue catalog, Athena—all wired up with encryption and dynamic partitioning. The same code I use.
The code for reproduction is free of charge and available here.